

© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Adrian Cockcroft’s architecture
trends and topics for 2021
Adrian Cockcroft
VP Cloud Architecture Strategy
AWS
A R C 2 1 3

© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Serverless first
Chaos engineering and failing over without falling over
Wardley Mapping for technology evolution
Hardware trends
Sustainability
Agenda

© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Serverless first

Trends: Microservices
MicroXchg Berlin event
where a group of speakers
including @adrianco
adopted the term

Start with serverless microservices
Definition from a talk by @adrianco in 2014

© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
We chose microservices to
get speed and agility . . .
So how long does it really
take to build a new
application from scratch?

AWS re:Invent
N O N - P R O F I T H A C K A T H O N F O R S O C I A L G O O D
SkyTruth
Best Friends
Animal Society
Several teams
of ~four people
Non-profit organization
with a problem
Monday, 8 AM
Here’s a set of
problems. Pick
one and build a
solution by 8 PM
this evening.
“
“
+ =

“
“
SkyTruth
Best Friends
Animal Society
Several teams
of ~four people
Non-profit organization
with a problem
Monday, 8 AM
Here’s a set of
problems. Pick
one and build a
solution by 8 PM
this evening.
+ =
AWS re:Invent
N O N - P R O F I T H A C K A T H O N F O R S O C I A L G O O D
Where would you start?

Every team used
AWS Lambda
1
Less than
a day total
2
Extremely functional
and scalable prototypes
4
Many team
members’ first time
using AWS Lambda
3
2016 AWS re:Invent Hackathon
A L I G H T B U L B M O M E N T

© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Note: See re:Invent 2019, SVS343
So . . . why doesn’t
everyone use
serverless first?

Language support
Scalability (new: 10 GB/6 vCPU)
Startup and network latency
Databases / storage interfacing
Security
State handling, event processing
Run duration
Complex configs (new: AWS Proton)
Portability (new: container support) Getting started
See my Serverless-First Function talk for a deep dive
https://aws.amazon.com/blogs/compute/icymi-serverless-first-function/
Common concerns

Update
S E R V E R L E S S S C A L E
AWS Lambda per-function
maximum disk space
Local
512 MB
Amazon EFS
Petabytes
47.9 TiB per file
June 2020 introduction of support for NFS mounting an
Amazon EFS file system – up to 25,000 concurrent connections
https://aws.amazon.com/blogs/compute/using-amazon-efs-for-aws-lambda-in-your-serverless-applications/

Update
S E R V E R L E S S - F I R S T C O N T A I N E R S
New support for
common build pipelines
delivering containers for
both runtimes
Serverless AWS Fargate
re:Invent 2020 introduction of AWS Lambda support for container packaging
and AWS Proton delivery tooling makes serverless first an even better choice!
Easier transition from spiky
workloads to Always On capacity

Bottom line
Serverless is the fastest way
to build a modern application
If you object, let us know what
we should work on next!

© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Chaos engineering
and failing over
without falling over

Chaos engineering definition
(Adrian’s concise version)
Experiment to ensure that the impact
of failures is mitigated

Trends – chaos engineering – 10 years on . . .
2010 – First Netflix blog post about Chaos Monkey

Past
Present
Future
?
Disaster
recovery
Chaos
engineering
Continuous
resilience
Resilience

We build redundancy into systems so that if
something fails, we can fail over to an alternative
However, our ability to fail over is complex and
hard to test, so often the whole system falls over

How can we do better?

The last strand that breaks is not the cause of a failure!
Build resilient systems like a rope, not a chain, but make sure you know how
much margin you have and how “frayed” your system is

Infrastructure
Switching
Application
People
Chaos
engineering
team
Tools
Security
red
team
Tools
Four layers, two
teams, an attitude
Experiment to
ensure that the
effect of failures
is mitigated
Chaos architecture
New! AWS Fault Injection Simulator
Run experiments to ensure that both availability and
performance impact of failures are mitigated

“You can’t legislate
against failure; focus on
fast detection and response.”
—Chris Pinkham
Observability Control

Let’s see what we can learn
from experts who have been
working on controlling safety
critical systems for decades


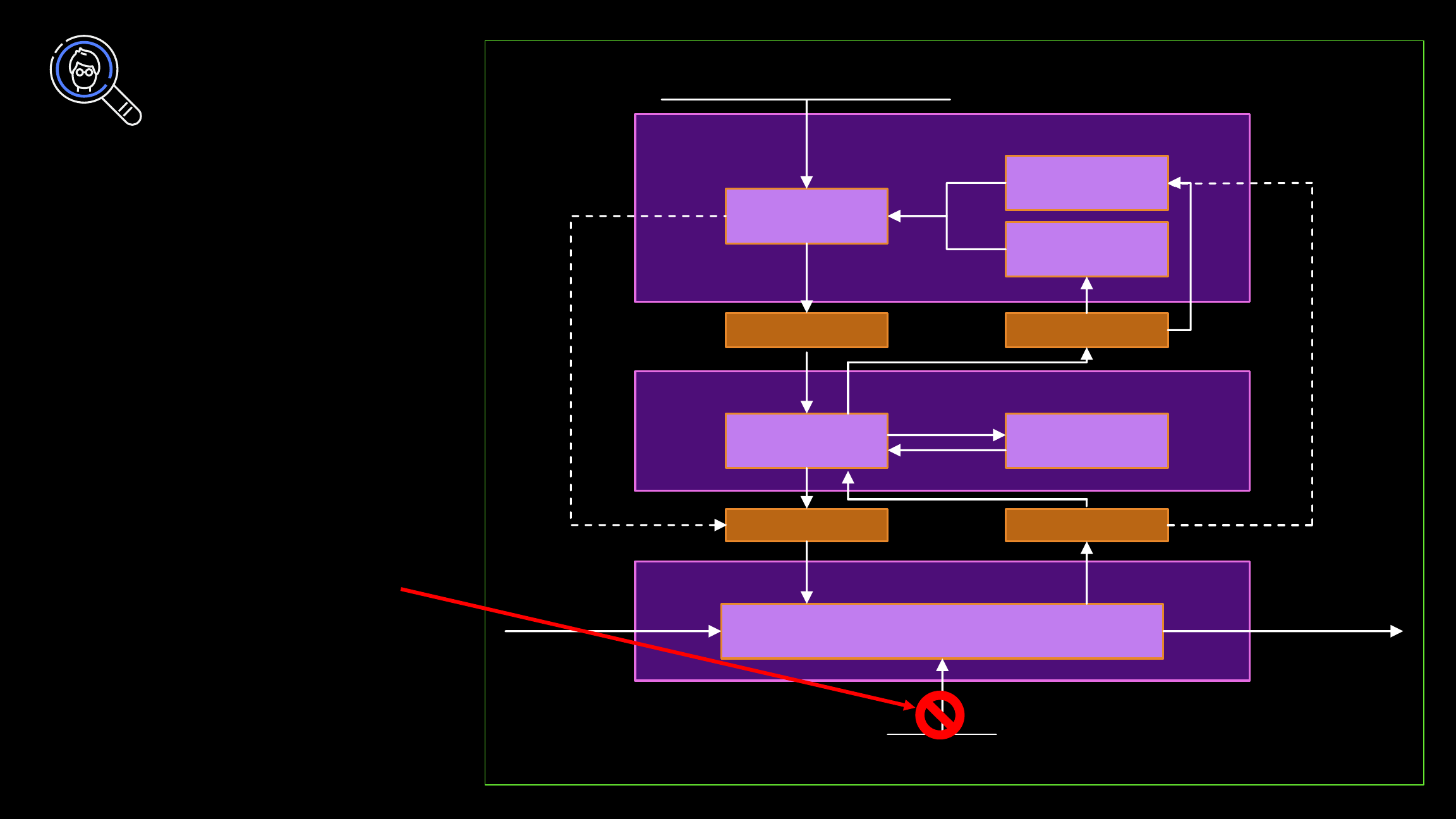
STPA model
control diagram
Understand hazards that
could disrupt successful
application processing
Observability
and control
Data plane
Throughput
Control plane
Human controller
Model of
automation
Model of
controlled process
DisplaysControls
Control algorithm
Model of
controlled process
Web service
SensorsActuators
Control action
generation
Environmental
inputs
Written / trained
procedures
Completed
actions
Customer
requests
Disturbances
Data plane
Throughput
Control plane
Human controller
Model of
automation
Model of
controlled process
DisplaysControls
Control algorithm
Model of
controlled process
Web service
SensorsActuators
Control action
generation
Environmental
inputs
Written / trained
procedures
Completed
actions
Customer
requests
Disturbances
What happens
if there is a
big enough
disturbance
to break the
web service?
Large-scale failure

Application is “out of control,” many possibilities
Automation has failed
Network partition, no route connecting application to customers
Application crashed or corrupted, not easily restartable
Anything else you didn’t think of
Trigger failover to alternative system
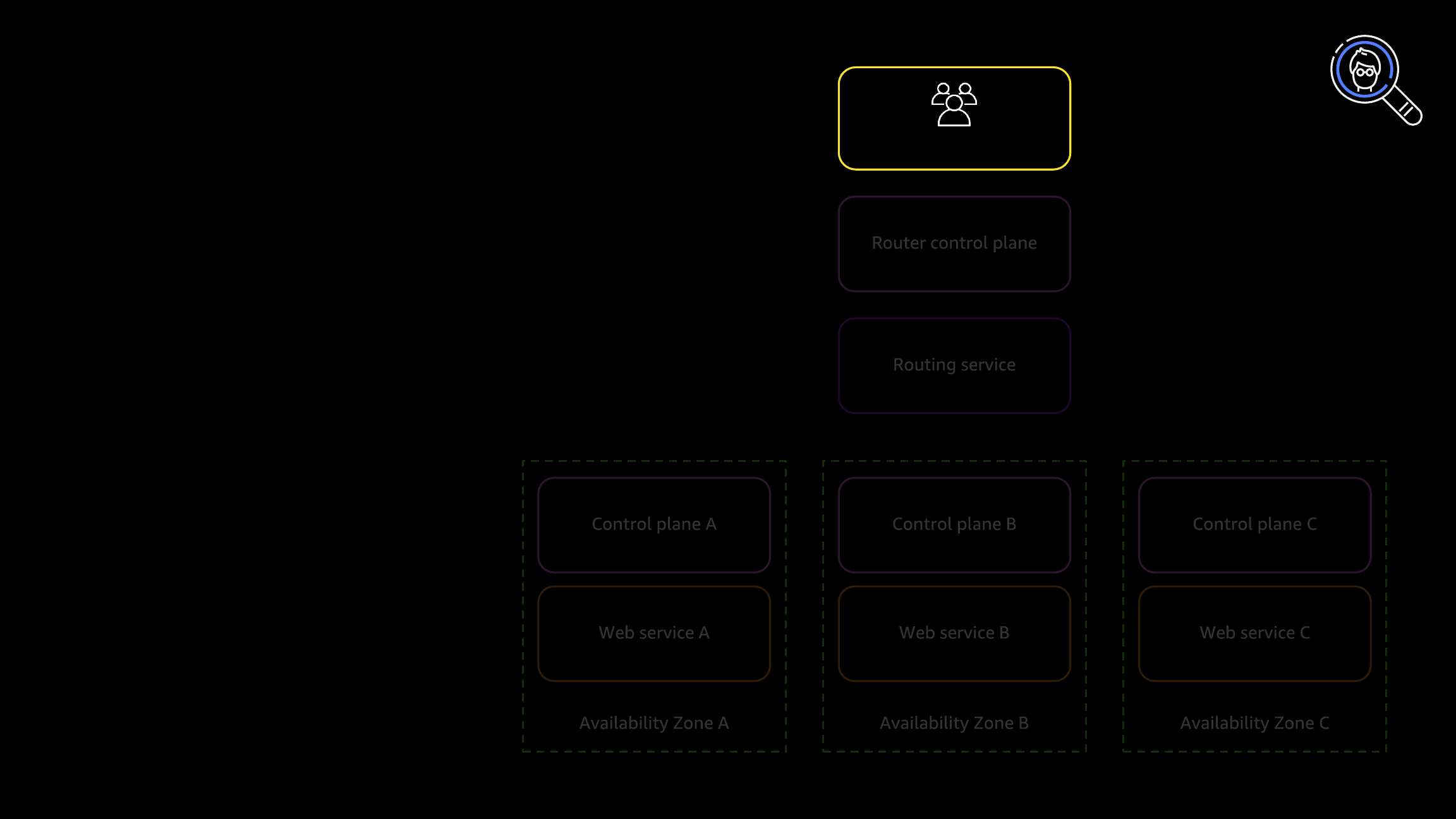
Large-scale failures

Human controllers
Router control plane
Routing service
Control plane A
Web service A
Availability Zone A
Control plane B
Web service B
Availability Zone B
Control plane C
Web service C
Availability Zone C
Symmetry
and assertions
• Services and data
are consistent across
three zones
• Zone failure modes
are independent
• Application should
work normally with
any zone offline
• Routing service
manages failover
Scenario
A W S A V A I L A B I L I T Y Z O N E S

Human controllers
Routing service
Control plane A
Web service A
Availability Zone A
Control plane B
Web service B
Availability Zone B
• Router control plane
detects offline AZ, stops
routing traffic
to it, and retries requests
on the online AZs
• Automated response;
what could go wrong?
Router control plane
Scenario
A W S A V A I L A B I L I T Y Z O N E S

Human controllers
Router control plane
Routing service
Control plane A
Web service A
Availability Zone A
Control plane B
Web service B
Availability Zone B
• Missing updates
• Zeroed
• Overflowed
• Corrupted
• Out of order
• Updates too rapid
• Updates infrequent
• Updates delayed
• Coordination problems
• Degradation over time
STPA hazards
S E N S O R M E T R I C S C H E C K L I S T
Routing control
plane doesn’t clearly
inform humans that
everything is taken
care of, and offline
zone delays and
breaks other metrics
with a flood of errors

Human controllers
Router control plane
Routing service
Control plane A
Web service A
Availability Zone A
Control plane B
Web service B
Availability Zone B
• Model mismatch
• Missing inputs
• Missing updates
• Updates too rapid
• Updates infrequent
• Updates delayed
• Coordination problems
• Degradation over time
STPA hazards
M O D E L P R O B L E M S C H E C K L I S T
Confused human
controllers disagree
among themselves
about whether
they need to do
something or not,
with floods of errors,
displays that lag
reality by several
minutes, and out-of-
date runbooks

Human controllers
Router control plane
Routing service
Control plane A
Web service A
Availability Zone A
Control plane B
Web service B
Availability Zone B
• Not provided
• Unsafe action
• Safe but too early
• Safe but too late
• Wrong sequence
• Stopped too soon
• Applied too long
• Conflicts
• Coordination problems
• Degradation over time
STPA hazards
H U M A N C O N T R O L A C T I O N C H E C K L I S T
Human controllers
should not need
to do anything!
However, they
are confused and
working separately,
trying to fix different
problems – some of
their tools don’t get
used often, and
are broken or
misconfigured to do
the wrong thing
Human controllers
Instead of failing
over, system
falls over
Most likely
result
In-rush of extra
traffic from failed
zone, and extra work
from a cross zone
request retry storm
causes zones A and B
to struggle and
triggers a complete
failure of the
application –
meanwhile, the
routing service also
has a retry storm
and is impacted

How to fail over without falling over
Alert correlation
Floods of alerts need to be reduced to actionable insights (new: Amazon DevOps Guru)
Observability system needs to cope with floods without failing
Run regular chaos engineering experiments (new: AWS Fault Injection Simulator)
Retry storms – prevent work amplification
Reduce retries to zero except at subsystem entry and exit points
Reduce timeouts to drop orphaned requests
Route calls within the same zone

Symmetries
High level of automation, consistent configuration as code
Consistent instance types, services, versions, zones, and Regions
Principles
If it can be the same, make it look and act identically
If it’s different, make that clearly visible
Test your assumptions continuously

What about multi-Region?
Get AZ failover solid
before attempting
multi-Region
Use STPA to
analyze multi-Region-
specific hazards
Follow
Well-Architected
guide patterns

As data centers migrate to the cloud, fragile
and manual disaster recovery processes
have been standardized and automated

Testing failure mitigation has moved from
a scary annual experience to automated
continuous resilience

© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Wardley Maps

Early adopters are using Wardley Maps

Maps always allow you to define position and movement
What is a Wardley Map?
Wardley Maps help define strategic context, barriers, and actions
Examples
• Evolution of technology from custom to utility
• Technology stack migrations from data center to cloud
• Make vs. buy decisions
• Open-source product strategy

Mapping open source for Kubernetes
Too many
projects in the cloud-
native landscape
All in
different stages
of evolution
So let’s try and
put some of them
on a map!


Projects outside CNCF CNCF projects Services
Mapping value chain against evolution
T H I S I S A M A P ! C L O U D - N A T I V E K U B E R N E T E S C O R E P R O J E C T S

Projects outside CNCF CNCF projects Services
New! AWS Grafana and Prometheus services
R E M E M B E R : A L L M A P S A R E W R O N G , B U T S O M E M A P S A R E U S E F U L – U S E T O F A C I L I T A T E D I S C U S S I O N

Results from mapping
Successful products and services due to better:
Shared understanding of moves
Situational awareness
Application of doctrines
Strategic decision-making

© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Hardware trends

Data that’s too big to process on one machine
What is “big data”?
But the machines keep getting bigger

EC2 UltraClusters
4 , 0 0 0 + A 1 0 0 G P U S O N 4 0 0 G B I T L I N K S I N T O P E T A B I T - S C A L E F A B R I C

Gigabits
bandwidth
10,000
100
10
320 GB
40 GB
1,100 GB
24,000 GB
4,400,000 GB
1,000
1
Memory capacity vs. bandwidth
Engulf your data
in memory to
reduce overhead
Internal memory bandwidth of A100
Terabyte+/second
Network bandwidth per node
comparable to Intel Cascade
Lake main memory bandwidth
EC2 UltraCluster
UltraCluster 4,000+ P4d
400 Gbit Ethernet
Network bandwidth
per node
AWS u24-tb1
8x Intel
Cascade Lake
main memory
Single
NVIDIA A100
1.2 TB/s
GPU memory
AWS P4d
8x NVIDIA A100
NVLINK 600 GB/s
GPU memory
AWS P4d
2x Intel Cascade Lake
main memory
Memory capacity

How can we take advantage of more memory?
In-memory analytics
(e.g., SAP HANA) is
mainstream today
Very large
graph databases
(it’s hard to partition graphs)
Use the memory
interconnect as a low-
latency network?
Put all the pods
and instances on
the same node?
Fast replication to
another node, in a
different AZ, for
persistence?
Use shared
memory to avoid
serialization overhead?

Interesting work to watch
Twizzler
UC Santa Cruz / Daniel
Bittman – data-oriented
operating system
Brytlyt
Database that runs
completely inside the GPU
MemVerge
Distributed
memory objects
SQream
GPU accelerated
data warehouse
Zenotech
GPU-based CFD simulation

© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Sustainability


Renewable
Energy
https://sustainability.aboutamazon.com/environment/sustainable-operations/renewable-energy


Amazon Sustainability Data Initiative
significantly reduces the
cost, time, and technical barriers
associated with analyzing large datasets to
generate sustainability insights
Data
Insights
Information Actionable knowledge

Weather &
climate
Remote
sensing
CMIP6 climate projections
LOCA downscaled climate projections
Atmospheric Models from Météo-France
NOAA’s Global Surface Summary of Day
HIRLAM Weather Model
NOAA Global Ensemble Forecast System (GEFS)
NOAA Global Forecast System (GFS)
NOAA High-Resolution Rapid Refresh (HRRR) Model
…
JMA Himawari-8
Landsat 8
NOAA GOES 16 & 17
Sentinel-1
MODIS MYD13A1, MOD13A1, MYD11A1, MOD11A1, MCD43A4
Terra Fusion Data Sampler
CBERS
…
Enabling easy access to petabytes of foundational data
Hosted free of charge in public Amazon S3 buckets
Managed and updated by data owners
Amazon Sustainability Data Initiative – ASDI



CALL TO ACTION
Use AWS services and open data
programs to architect solutions and
achieve your sustainability goals
Look for opportunities to optimize
your architecture
Share the solutions you build to support
sustainability goals and collaborate with
others in your industry and cross-sector

Resources
Related re:Invent 2020 talks
ARC207 – Architecting resiliency, recovery, and reliability: Capital One
ARC307 – Going global in minutes: Multi-Region expansion simplified (Autodesk)
ARC316 – Testing resiliency using chaos engineering
Related blog posts
“Failing over without falling over”:
https://stackoverflow.blog/2020/10/23/adrian-cockcroft-aws-failover-chaos-engineering-fault-tolerance-distaster-recovery
Full Serverless-First talks: https://aws.amazon.com/blogs/compute/icymi-serverless-first-function
Response time variation: https://dev.to/aws/why-are-services-slow-sometimes-mn3
Retries and timeouts: https://dev.to/aws/if-at-first-you-don-t-get-an-answer-3e85
Paper
“Building Mission-Critical Financial Services Applications on AWS,” by Pawan Agnihotri with contributions by Adrian Cockcroft:
https://d1.awsstatic.com/Financial%20Services/Resilient%20Applications%20on%20AWS%20for%20Financial%20Services.pdf
Book recommendations
Reading list at: http://a.co/79CGMfB
Adrian Cockcroft
@adrianco

© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
AWS Well-Architected Framework
The official best practices for architecting in the AWS Cloud
aws.amazon.com/architecture/well-architected
AWS Well-Architected Labs
Hands-on labs to help you learn, measure, and build using architectural best practices
wellarchitectedlabs.com
AWS Architecture Center
Official AWS repository for all architecture resources
aws.amazon.com/architecture
AWS Solutions Library
Vetted reference implementations and Well-Architected patterns
aws.amazon.com/solutions
Architecture resources

Thank you!
© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Adrian Cockcroft
@adrianco

© 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
